카프카 사용 이유
메시지가 생성되었을 때 실시간 처리를 위해 Redis나 Memcached를 사용할 수 있다. 그러나 데이터를 메모리에 저장하기 때문에 장기간 보관하기엔 불안정하다. expired time이 지정되어 있지 않은 경우 메모리가 꽉 차면 문제가 생길 수 있다.
반면 카프카는 파일 시스템에 저장해서 안정적이다. Transaction Per Seconds가 다른 Message Queue에 비해 높다. consumer가 broker(kafka)에서 메시지를 pull하는 방식이라 consumer가 처리할 수 있는 대로 메시지를 효율적으로 처리할 수 있다. 다른 경우는 broker가 consumer에게 직접 메시지를 push하는 데 이 경우 consumer의 자원 등을 고려하지 않기 때문에 효율적이지 못하다.
카프카는 분산 스트리밍 플랫폼이다
스트리밍 플랫폼은 세가지 능력이 있다.
1. 메시지 큐, 엔터프라이즈 메시지 시스템과 유사한 레코드 스트림을 발행하고 구독한다.
2. 내결함성이 있는 내구성 방식의 레코드 스트림을 저장한다.
3. 레코드 스트림이 발생하면 처리한다.
카프카는 일반적으로 두가지 앱 클래스에 사용된다.
1. 시스템과 앱 간 안정적으로 데이터를 받는 실시간 스트리밍 데이터 파이프라인 구축
2. 데이터 스트림을 변환하거나 응답하는 실시간 스트리밍 앱 구축
카프카 개념
카프카는 여러 데이터센터로 확장할 수 있는 하나 이상의 서버 클러스터로써 실행된다.
카프카 클러스터는 topic이라 부르는 카테고리에 레코드 스트림을 저장한다.
각 레코드는 키, 값, 타임 스탬프로 구성된다.
카프카 용어
producer : 메시지 생산자. 앱이 하나 이상의 카프카 topic에 레코드 스트림을 발행하게 한다.
consumer : 메시지 소비자. topic에 담긴 메시지를 처리함
broker : 카프카
zookeeper : 공개 분산형 구성 서비스. 카프카의 상태와 클러스터를 관리한다.
cluster : 브로커 cluster
topic : 메시지 종류
partition : topic 내부 단위
log : 메시지
offset : 파티션 내 각 메시지의 식별자
단순히 보면 kafka라는 broker를 매개로 producer가 topic에 메시지를 생성하면 consumer가 메시지를 가져다 처리한다.
카프카 구조
topic
topic은 레코드가 발행되는 카테고리나 피드 이름이다. 카프카 내 topic들은 항상 멀티 구독자인데 이 말은 topic은 작성된 데이터를 구독하는 소비자를 0 이상 가질 수도 있다는 것이다.
각 topic에 대해 카프카 클러스터는 파티션된 로그를 유지한다.
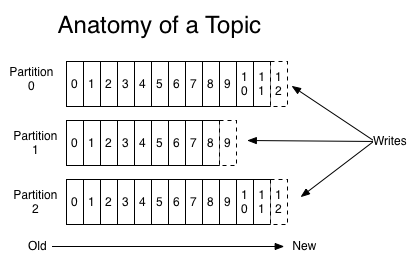
구조화된 커밋 로그에 지속적으로 추가되는 불변의 레코드 순서로 각 파티션은 정렬된다. 파티션 내 레코드들은 각각 파티션 내에서 각 레코드를 유일하게 식별하는 offset이라 불리는 순차적 id를 할당받는다.
카프카 클러스터는 구성 가능한 유지 기간을 써서 모든 발행된 레코드들을 소비가 됐던 안됐던, 견고하게 지속한다. 예를 들어, 만약 리텐션 정책이 2일로 설정되면, 레코드가 발행된지 2일 내 소비가 가능해지고, 공간을 비우기 위해 삭제된다. 카프카의 성능은 데이터 크기와 관련하여 일정하므로 오랜 기간 데이터를 저장하는 것은 문제가 아니다.

카프카는 topic에 메시지를 바이트 배열 형태로 저장한다.
보관 기간 : default 7일, 설정 가능
공간 유지 정책 : 메시지가 설정 값이 되면 메시지가 삭제 되게 함
offset : 메시지에는 offset이 있다. topic 내 partition에 메시지가 순차적으로 저장된다. consumer는 offset을 기준으로 처리했는지 처리하지 않았는지 나눈다.
partition : 메시지 topic은 파티션으로 구성되어 분산 처리된다.
partition
메시지는 파티션에 추가되고 메시지는 offset에 맞게 할당된다.
메시지가 파티션에 시간 순서대로 할당됐더라도 파티션이 여러개라면 방식에 따라 consumer 입장에선 순차적으로 메시지를 처리할 수 없을 수 있다. 파티션을 한 개만 두고 처리하는 방법을 고려해야 한다.
producer
생산자는 메시지 쓰기 요청을 생성해서 리더 브로커에게 전달한다. 파티셔너는 메시지의 해시 값으로 생산자가 어떤 파티션에 메시지를 pub할지 알게 한다.
해시 값은 메시지 키로 계산하고 메시지 키는 카프카의 토픽에 메시지를 기록할 때 제공된다. 파티션은 하나의 리더를 가진다. 읽기, 쓰기는 리더를 통해 수행된다.
consumer
카프카의 topic을 구독한다. 소비자는 소비자 그룹에 속한다. 동일 그룹 내 소비자들은 같은 토픽 내 서로 다른 파티션에서 메시지를 가져온다. 서로 영향을 미치지 않는다.
zookeeper
컨트롤러 선정 : 파티션 관리를 하는 브로커. 파티션 관리는 리더 선정, topic 생성, 파티션 생성, 복제본 관리 등. 노드, 서버가 꺼지면 팔로워 중에서 파티션 리더를 정한다. 카프카는 컨트롤러를 정하기 위해 주키퍼 메타 데이터를 이용.
브로커 메타 데이터 : 카프카 클러스터의 브로커에 대한 상태 정보
토픽 메타 데이터 : 파티션 수 등 토픽 메타 데이터
https://kafka.apache.org/intro
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
https://coding-start.tistory.com/192?category=790331
Apache Kafka - Kafka(카프카)란 ? 분산 메시징 플랫폼 - 1
이전 포스팅들에서 이미 카프카란 무엇이고, 카프카 프로듀서부터 컨슈머, 스트리밍까지 다루어보았다. 하지만 이번 포스팅을 시작으로 조금더 내용을 다듬고 정리된 상태의 풀세트의 카프카 포스팅을 시작할 것..
coding-start.tistory.com